Introduction
In recent years, large language models (LLMs) have demonstrated remarkable abilities in solving mathematical exercises, proposing new mathematical theorems, predicting the structure of proteins, and other surprising behaviors. Unfortunately, many of these models are not open-source and cannot be used by the community. However, META has announced a new language model trained on a massive amount of public data. The best part is Its open-source.

What is LLaMA
LLaMA (Large Language Model Meta AI) is a new AI language generator developed by Meta, Facebook’s parent company, that is designed to help researchers advance their work in the subfield of AI. It is not a system that anyone can talk to, but rather a research tool that requires prompt engineering. LLaMA is an auto-regressive language model based on the transformer architecture and comes in four different sizes, ranging from 7B to 65B parameters. The model was trained on large amounts of publicly available data, containing trillions of text samples from 20 different languages, but the majority of the data is in English. LLaMA is a foundational model and is not intended for downstream applications without additional risk assessment and mitigation.
Main Purposes of LLaMA
- LLaMA large language model was designed to investigate possible applications, such as question answering, natural language comprehension, and reading comprehension. Researchers can use the model to explore different use cases and evaluate its performance in various tasks.
- The model’s diverse data sources and multiple sizes make it a versatile tool for researchers. LLaMA can be used to examine the capabilities and limitations of existing language models and compare them with LLaMA’s performance.
- LLaMA large language model can help researchers develop strategies to enhance language models. By studying the model’s performance and identifying its strengths and weaknesses, researchers can develop new techniques to improve language models.
- Meta recognizes the potential risks associated with AI language models, such as the generation of biased, harmful, or unhelpful content. LLaMA was designed to evaluate and manage these risks by measuring the model’s biases, toxicity, and hallucinations.
- LLaMA was also designed to solve complex mathematical theorems. The model’s auto-regressive language model based on the transformer architecture makes it capable of processing and analyzing large amounts of mathematical data.
- LLaMA large language model can also be used to predict new protein structures. The model’s diverse data sources and multiple sizes make it an ideal tool for analyzing large amounts of genomic data.
LLaMA Architecture
The LLaMA model was developed between December 2022 and February 2023 by the FAIR team of Meta AI. It is the first version of the model, and it is an auto-regressive language model, based on the transformer architecture. The model has four different sizes, which are 7B, 13B, 33B, and 65B parameters. The pre-training data is a mixture of many open datasets of diverse domains, which helps LLaMA to achieve few-shot capabilities.
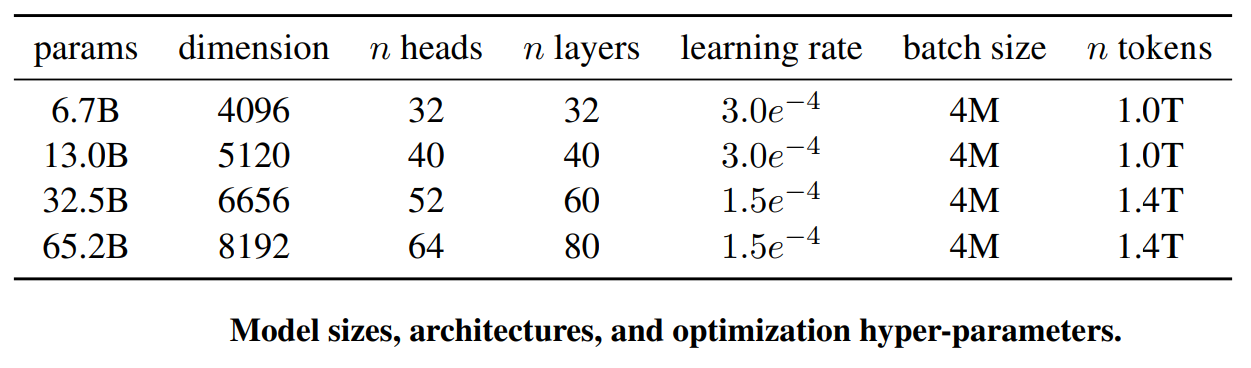
Pre-normalization using RMSNorm
LLaMA normalizes the input of each transformer sub-layer, instead of normalizing the output. This is inspired by GPT-3 and is done using RMSNorm, which is an extension of Layer Normalization (LayerNorm). The reason behind using RMSNorm is the computational overhead in LayerNorm, which makes improvements slow and expensive. RMSNorm achieves comparable performance against LayerNorm but reduces the running time by 7% to 64%.
SwiGLU activation function
LLaMA uses the SwiGLU activation function, which is inspired by PaLM. SwiGLU is based on the Swish activation function and is used to gate the output of each transformer sub-layer. It is done by multiplying the output with a gating value that is obtained by applying the Swish activation function on a portion of the input.
Rotary Embeddings (RoPE)
RoPE is a type of position embedding that encodes absolute positional information with a rotation matrix. It naturally incorporates explicit relative position dependency in self-attention formulation and decays inter-token dependency with increasing relative distances. RoPE is used in LLaMA to encode relative position by multiplying the context representations with a rotation matrix.
LLaMA Pre-training Data
The diversity of data sources used to train LLaMA is a key factor in its versatility as a research tool. The model was trained in 20 different languages, but due to the majority of the training data being in English, it is expected to perform better in English than in other languages. It is important to note that the use of publicly available data sources does have some limitations. For example, these sources may contain biases or inaccuracies that can affect the model’s performance. To mitigate these risks, the FAIR team performed bias evaluations on the LLaMA model.
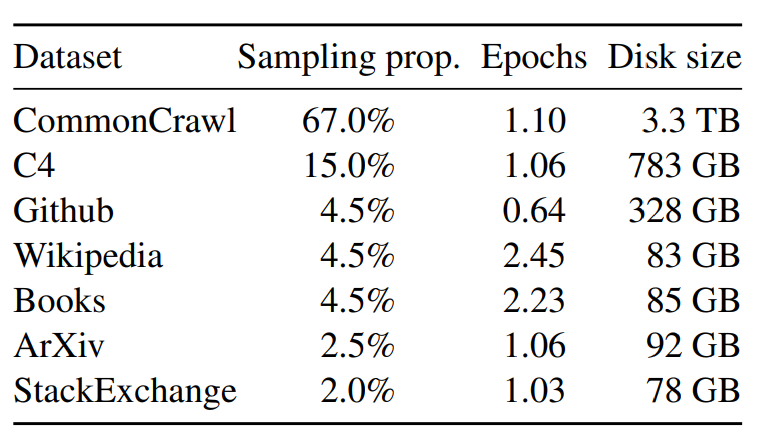
As shown in Image, the majority of the data used to train LLaMA comes from CCNet, which makes up 67% of the total training set. CCNet is a large-scale, high-quality web-crawled corpus that covers a wide range of topics and domains. The other data sources used, such as C4, GitHub, Wikipedia, books, ArXiv, and Stack Exchange, provide additional domain-specific information and help to create a more diverse training set.
LLaMA outperforming GPT-3 and competing with top models
- LLaMA is a collection of language models with different sizes, ranging from 7 billion to 65 billion parameters.
- The models were trained on large amounts of publicly available data, containing trillions of text samples.
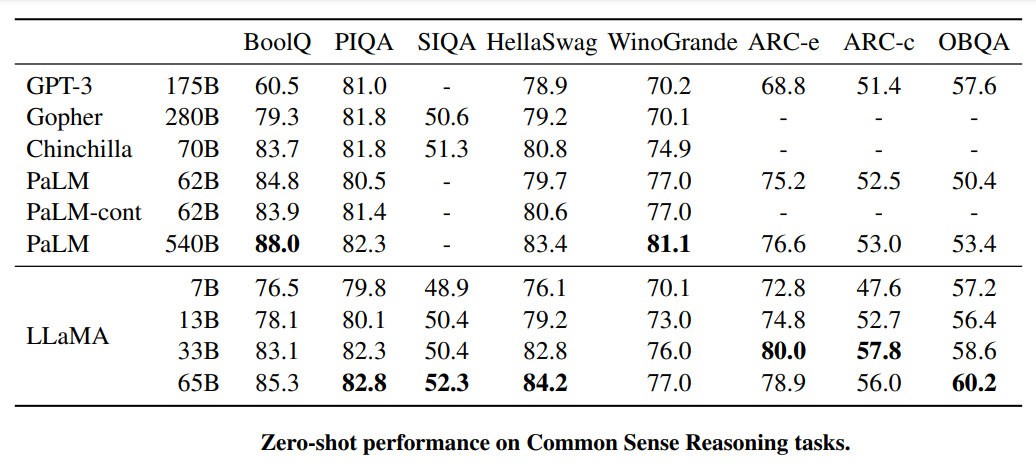
- LLaMA-13B outperformed GPT-3 (175B) in most tests or evaluations despite being more than 10× smaller.
- LLaMA-65B was found to be comparable to some of the best-performing models such as Chinchilla70B and PaLM-540B.
- LLaMA’s success suggests that it has been optimized for efficient training and inference, which could make it an attractive option for real-world applications.
- LLaMA’s performance improvements have the potential to greatly improve the capabilities of natural language processing systems.
How can the LLaMA model be used?
The LLaMA large language model can be used for a variety of tasks, including:
Chatbots: The LLaMA model can be used to create chatbots that can have natural conversations with humans.
Translation: The LLaMA model can be used to translate text from one language to another.
Question answering: The LLaMA model can be used to answer questions about a wide range of topics.
Text generation: The LLaMA model can be used to generate text, such as poems, code, scripts, musical pieces, email, letters, etc.
Content creation: The LLaMA model can be used to generate creative content, such as blog posts, articles, and social media posts.
Data analysis: The LLaMA model can be used to analyze large amounts of data and extract insights.
Bias in training data: As LLaMA is trained on data collected from the web, there is a risk that the data contains biases and harmful content that could be perpetuated by the model.
Harmful content generation: Large language models like LLaMA are capable of generating text, which can include harmful, offensive, or biased content. This could have negative consequences if the text is used for malicious purposes.
Human life impact: LLaMA is not intended to inform decisions about matters central to human life, and should not be used in such a way. Using the model for such critical decision-making could lead to serious harm.
Transparency and accountability: The developers of LLaMA have a responsibility to ensure transparency and accountability in the use of the model. This includes disclosing any biases in the training data and taking steps to mitigate the risks associated with the use of the model.
Responsible use: The potential for misuse of LLaMA is high, and it is important that the model is only used for ethical and responsible purposes. Any use of the model must be closely monitored to ensure that it does not generate misinformation or harmful, biased, or offensive content.
Mitigations: The use of mitigation strategies like filtering the data from the web based on proximity to Wikipedia text and references is a positive step towards reducing the potential for harmful, offensive, or biased content in the model. However, these measures may not be sufficient to eliminate all biases and harmful content.
Conclusion
LLaMA large language model is an exciting development in the field of AI language models, and its release to the research community could have significant implications for the future of this technology. The model’s versatility, outperformance of GPT-3 on most benchmarks, and bias evaluation results are all factors that make it an important tool for researchers looking to develop and improve language models. As long as the appropriate measures are taken to manage and mitigate risks associated with AI models, LLaMA has the potential to accelerate progress in this field and drive meaningful innovation.
You can also check BLOOM large language model and cohere.ai language model.