In this blog post we will discuss about Vicuna Open-Source Large Language Model. Vicuna is an Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality.

Introduction
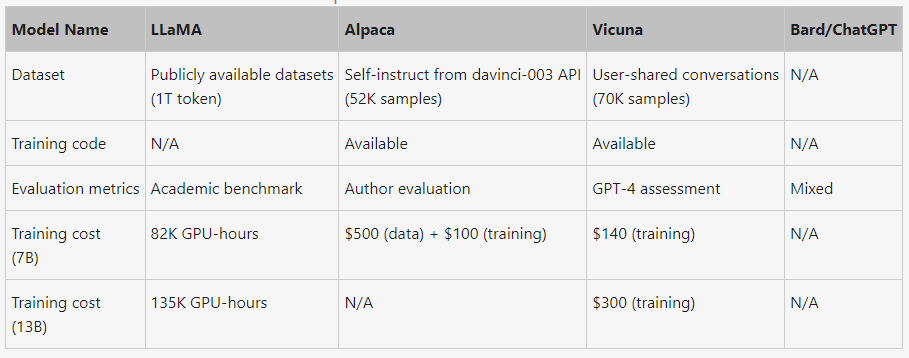
Vicuna-13B is an open-source chatbot developed by a team of researchers from UC Berkeley, CMU, Stanford, and UC San Diego. The chatbot is based on the transformer architecture and is trained using fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Its primary use is for research on large language models and chatbots, and it is intended for use by researchers and hobbyists in natural language processing, machine learning, and artificial intelligence. Preliminary evaluations show that Vicuna-13B achieves more than 90% quality of OpenAI ChatGPT and Google Bard and outperforms other models like LLaMA and Stanford Alpaca in more than 90% of cases, with a training cost of around $300. The code and weights, along with an online demo, are publicly available for non-commercial use.
The Architecture
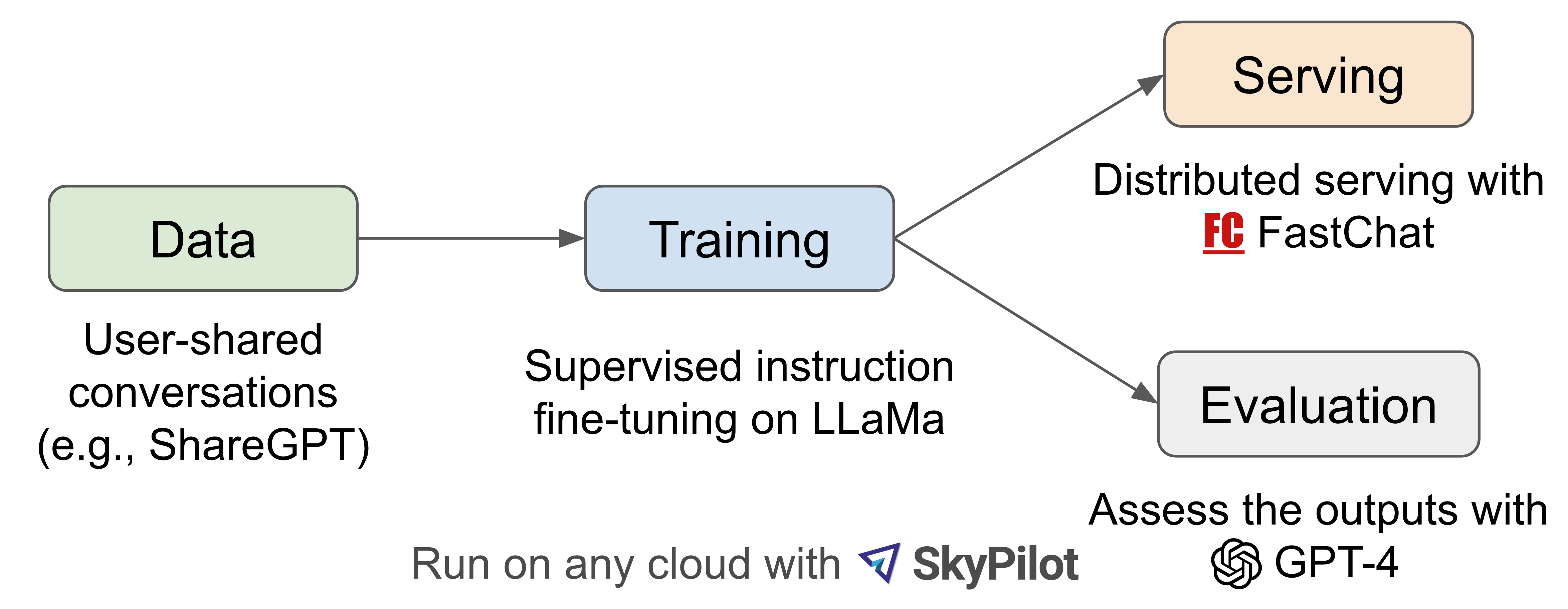
Large language models (LLMs) have revolutionized chatbot systems, but the training and architecture details of OpenAI’s ChatGPT are unclear. The authors introduce Vicuna-13B, an open-source chatbot that uses a LLaMA base model fine-tuned on user-shared conversations from ShareGPT.com. They enhanced the training scripts provided by Stanford Alpaca, and the model’s performance is competitive with other open-source models. The article provides a preliminary evaluation of Vicuna-13B’s performance and describes its training and serving infrastructure, and invites the community to test the chatbot using an online demo. The authors collected around 70K conversations from ShareGPT.com, enhanced the training scripts, and used PyTorch FSDP to train the model on 8 A100 GPUs in one day. They also conducted a preliminary evaluation of the model’s quality by creating a set of 80 diverse questions and utilizing GPT-4 to judge the model outputs.
A detailed comparison of LLaMA, Alpaca, ChatGPT, and Vicuna is shown in Table 1 below.
Training
Vicuna an open source large language model. To develop Vicuna, The team fine-tuned a LLaMA base model using around 70K user-shared conversations obtained from ShareGPT.com via public APIs. they took measures to ensure data quality by converting the HTML back to markdown and filtering out unsuitable or low-quality samples. Furthermore, they divided lengthy conversations into smaller segments that fit the maximum context length of the model.
Our training recipe builds on top of Stanford’s alpaca with the following improvements.
Memory Optimizations: To improve Vicuna’s ability to comprehend longer contexts, we increase the maximum context length from 512 (in Alpaca) to 2048, which results in a significant increase in GPU memory requirements. To mitigate the memory pressure, we employ techniques such as gradient checkpointing and flash attention.
Multi-round conversations: We modify the training loss to consider multi-round conversations and calculate the fine-tuning loss based only on the chatbot’s output.
Cost Reduction via Spot Instance: To address the challenge of higher training expenses due to a larger dataset and longer sequence length, we utilized SkyPilot managed spot instances that allow us to leverage cheaper spot instances with auto-recovery for preemptions and auto zone switch. This approach significantly reduced the cost of training the 7B model from $500 to approximately $140 and the 13B model from around $1K to $300.
Serving
We build a serving system that is capable of serving multiple models with distributed workers. It supports flexible plug-in of GPU workers from both on-premise clusters and the cloud. By utilizing a fault-tolerant controller and managed spot feature in SkyPilot, this serving system can work well with cheaper spot instances from multiple clouds to reduce the serving costs. It is currently a lightweight implementation and we are working on integrating more of our latest research into it.
How Good is Vicuna?
We improved Vicuna by training it with 70K chat conversations from users, and found that it can now give more detailed and organized responses than Alpaca. Its quality is similar to that of ChatGPT.
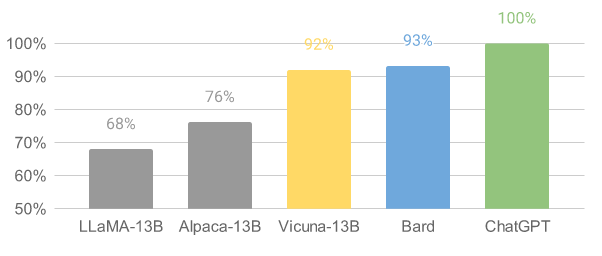
It’s not easy to evaluate chatbots, but we are interested in using GPT-4 to automatically assess them. Our initial results show that GPT-4 can rank chatbots and assess their answers consistently. We used GPT-4 to evaluate Vicuna, and it performed at 90% of the level of Bard/ChatGPT. However, this approach is not yet perfect and needs more research to be rigorous. We provide more details in the evaluation section.
How To Evaluate a Chatbot?
Evaluating chatbots powered by artificial intelligence (AI) is a complex task, as it involves examining their ability to understand language, reason, and comprehend context. With the increasing sophistication of AI chatbots, existing benchmarks may no longer be sufficient. For example, the evaluation dataset used in Stanford’s Alpaca, self-instruct, can be effectively answered by state-of-the-art (SOTA) chatbots, making it difficult for humans to distinguish differences in performance. Other limitations include data contamination during training/testing and the high cost of creating new benchmarks. To address these issues, a team proposes an evaluation framework based on the GPT-4 model to automate chatbot performance assessment.
The team created eight question categories, such as Fermi problems, roleplay scenarios, and coding/math tasks, to test various aspects of a chatbot’s performance. Using careful prompt engineering, GPT-4 generates diverse and challenging questions that baseline models have difficulty answering. The team collected answers from five chatbots: LLaMA, Alpaca, ChatGPT, Bard, and Vicuna. They asked GPT-4 to rate the quality of their answers based on helpfulness, relevance, accuracy, and detail. GPT-4 can produce relatively consistent scores and provide detailed explanations of why such scores are given. However, GPT-4 struggles to judge coding/math tasks.
The team compared the results of GPT-4 with other baseline models and Vicuna. GPT-4 preferred Vicuna over open-source models (LLaMA, Alpaca) in more than 90% of the questions, and it achieved competitive performance against proprietary models (ChatGPT, Bard). In 45% of the questions, GPT-4 rated Vicuna’s response as better or equal to ChatGPT’s. GPT-4 assigned a quantitative score to each response on a scale of 10, and the team calculated the total score for each (baseline, Vicuna) comparison pair by adding up the scores obtained by each model on 80 questions. Vicuna’s total score was 92% of ChatGPT’s score. Despite recent advancements, chatbots still face limitations, such as struggling with basic math problems or having limited coding ability.
While the proposed evaluation framework shows promise in assessing chatbots, it is not yet a rigorous or mature approach, as large language models are prone to hallucinate. Developing a comprehensive, standardized evaluation system for chatbots remains an open question requiring further research.
Limitations
Like other large language models, Vicuna has some shortcomings that we have observed. One of these is its inadequacy in tasks requiring reasoning or mathematics, and it may not be entirely reliable in verifying its outputs or identifying itself correctly. Moreover, we have not yet fully optimized Vicuna to ensure safety or address any potential toxicity or bias. To mitigate any safety concerns, we have integrated the OpenAI moderation API to filter out any inappropriate user inputs in our online demo. However, we recognize that Vicuna can be an excellent starting point for future research to overcome these limitations.
Conclusion
Large language models (LLMs) like OpenAI’s ChatGPT have greatly improved chatbot systems. However, the lack of information regarding the training and architecture of ChatGPT has limited further research and development in this field. In response, a new open-source chatbot called Vicuna-13B has been created by fine-tuning a LLaMA base model using conversations shared by users. Vicuna-13B has shown impressive results compared to other open-source models, and this blog post provides details on its architecture, performance and infrastructure.